


Recently, with the increased reliance on video-based teleconferencing, several vendors have integrated foreground extraction tools in their systems, enabling their users to select between several static or dynamic backgrounds, replacing their physical environment by a virtual one. These solutions also enable TV viewers at home to be incorporated into a live program they are watching and to interact with people or computer-generated elements in the studio. In the AdMiRe project we investigate efficient solutions for the aforementioned applications. An essential part of those solutions is foreground extraction, which can be challenging in an uncontrolled environment.
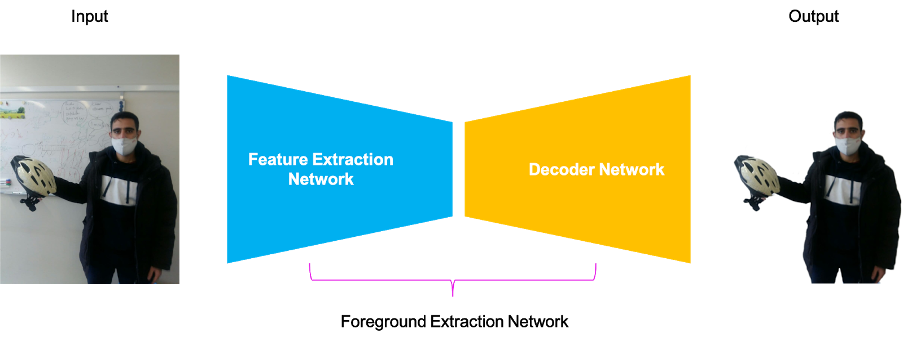
To this end, EPFL designed a convolutional neural network (CNN) for the foreground extraction task. A high-level block diagram of our network is shown in the figure above.
As can be seen, the input image is fed to the network which consists of two main parts: a feature extraction (encoder) which aims at extracting (encoding) important information from the input image and a decoder network which aims at constructing the foreground mask using the encoded information. After applying the corresponding mask, we can obtain the foreground as the output of our algorithm.
Several lightweight architectures are explored for both networks to find the best solution, which performs not only accurately, but also in real-time.
Our current solution relies on over 400’000 parameters which can process a minimum of 24 frames per second of HD video on a GeForce GTX1080. Further optimizations are under way to increase the real-time performance.
Similar to the state of the art in this domain, we used pixel-wise intersection over union (IOU) as a performance metric which leads to above 97% pixel-wise IOU when applied to a human indoor dataset.